Anatomy of a cryptographic collision – the “Sweet32” attack
Researchers at the Institute for Research in Computer Science and Automation in France (INRIA) have come up with the latest BWAIN.
A BWAIN ia a Bug With An Impressive Name, and this one has a logo, too:

Sweet32 is a way to attack encrypted web connections by generating huge amounts of web traffic, in the hope that the encryption algorithm in use will eventually (and entirely by chance) leak a tiny bit of information about the traffic it’s encrypting.
Sweet32, by the way, is a play on “sweet sixteen,” with the number 32 chosen because it’s half of 64.
That all sounds rather mysterious, so we’ll do our best to explain.
Block ciphers
Data in encrypted web connections is usually encrypted with what’s called a block cipher, such as the well-known Advanced Encryption Standard (AES) algorithm.
As the name suggests, block ciphers work on chunks of data at a time, usually 16 bytes (128 bits).
By mixing up a whole block every time, a block cipher not only has plenty of material to involve in its scrambling process, but also produces output a whole block at a time, which is efficient.
Of course, while you’re encrypting, you will get the same block of scrambled output every time you put in the same block of plaintext input, which is no good if you’re encrypting a message with repetition or predictable structure.
Every time you had 16 spaces in a row, or a common string of text such as GET /index.html HTTP/1.1, you’d have a recognisable pattern in the output to match the repetition in the input.
Even if the attacker can’t guess what WR9RFJKW88RFW$#D stands for in the ciphertext, he can see when it repeats, which gives away information about the plaintext – and a good cipher is supposed to prevent that happening.
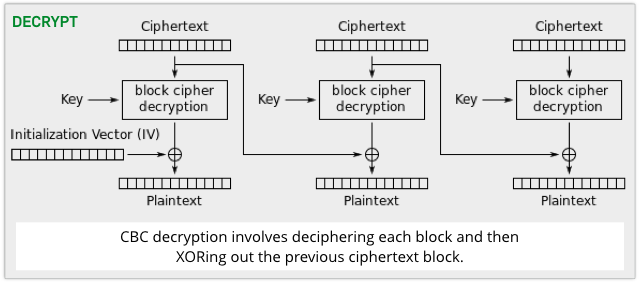
So, to disguise patterns in the input, block ciphers are often used in CBC mode, short for Cipher Block Chaining.
CBC is a security enhancement that XORs the previous block of ciphertext with the current block of plaintext before encrypting each block.
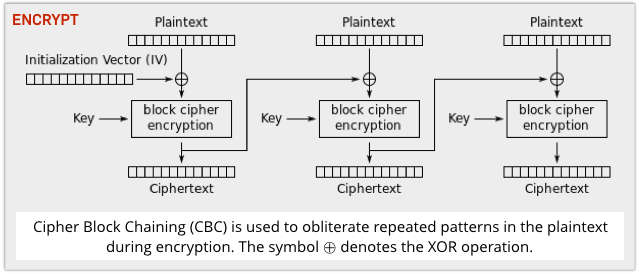
The first plaintext block, of course, doesn’t have any previous ciphertext to draw on, so it is XORed with a random starting block known as the Initialisation Vector, or IV.
CBC ensures that a run of identical blocks, such as a sector’s worth of zeros, won’t encrypt into a recognisably repeating pattern of ciphertext blocks.
That’s because of the the random IV mixed in at the start, and the randomness that then percolates through the encryption of each subsequent block.
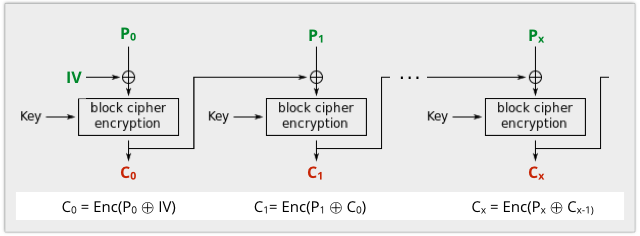
If we use P for plaintext, C for ciphertext (the encrypted output), Enc to denote the encryption function and x to count the block numbers (starting from zero), then:
The birthday attack
Remember that we’re using CBC to prevent repeating patterns in the input from repeating in the output as well.
But there’s nothing to stop two output blocks in the same encrypted message from ending up the same, entirely by chance.
In theory, the output of a block cipher in CBC mode is indistinguishable from random data, so the chance of a repeat, given that there are a whopping 2128 different 128-bit blocks, should be negligible.
But some websites and VPNs still use old ciphers that use 64-bit blocks, because smaller blocks were easier to deal with on older computers, which had slower processors and less memory.
The algorithms 3DES and Blowfish, for example, both use 64-bit blocks for encryption.
Even so, there are 264 possible ways to arrange the bits in a 64-bit block, giving about 18 million million million different blocks.
So you’re probably thinking that the chance of a collision – two identical output blocks appearing within a single encryption session – is as good as zero.
For example, if you generated 232 random blocks, you might guess that you’d have a 232 out of 264 chance of a collision, odds of one in four billion.
But the chance is much, much bigger than that, and here’s why.
Amongst your 4 billion blocks (232), you aren’t looking for a specific block to appear twice.
You’re looking for any pair of blocks that happen to be the same, whatever their value might be.
It’s like going to a cocktail party and saying, “I wonder if two people in this room right now have the same birthday?”
If there are only 50 people present, you might assume it was unlikely, given that there are 365 days in the year.
That’s because most people conceptualise this problem as if it said, “I wonder if anyone else in the room has the same birthday as me?”
In fact, with 50 people in the room, a shared birthday is close to certain, and we can show this quite easily “in reverse,” by calcuating the probability that everyone in the room has a different birthday.
The first person can have any of the 365 days in the year; the second must have any of the 364 days that don’t match the first; the third must have any of the 363 that don’t match the previous two, and so on.
We need to multiply out the probabilities that each person’s birthday avoids all the days chosen so far, like this:

That comes out at 3%, meaning that with 50 people, the chance that at least two people share a birthday is (100% – 3%), or an amazing 97%.
Indeed, you need only 23 people to get better than 50-50 odds that there’s a a shared birthday in the room.
When we make the numbers much bigger, you get to those 50-50 odds of a collision when you have 232 different samples selected from 264 possibilities.
Loosely speaking, when there are 2N possibilities and you randomly pick just 2N/2 samples, the chance of a “birthday collision” is at even money, or 50%.
This is called the birthday paradox because many people’s intuition tells them that the answer should be 2N divided by 2, but it’s actually the square root of 2N.
(Now you know where the name Sweet32 comes from, because 32 is half of 64, and 3DES and Blowfish have 64-bit blocks.)
The attack
What the researchers did is this:
- Wait for the victim to login to the target site, thus setting a login cookie that the browswer will submit in future HTTP requests.
- Entice the victim to a website with JavaScript that generates billions of requests to the target site. (Each one will contain the login cookie.)
- Sniff the network traffic and store it all up until there’s a collision in the encrypted data blocks.
- Use the trick described below to decrypt the login cookie.
That sounds easy, but there are some big “ifs” here.
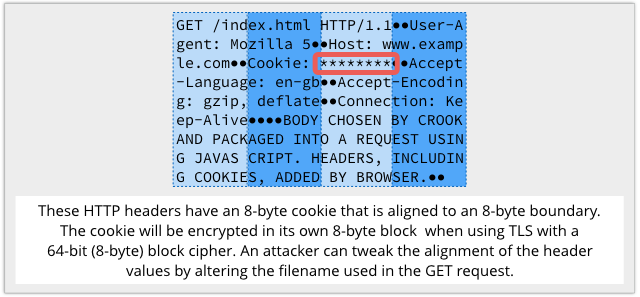
Firstly, the target site has to set a login cookie in a predictable way and at a precisely known position in the encrypted HTTP data blocks.
Secondly, the target site has to open a single HTTP connection and keep it open for millions of HTTP requests, during which somewhere around 1TB of data will be exchanged.
Thirdly, the collision can’t involve just any two encrypted blocks: one has to be a block that contains the unknown login cookie data, and the other must be a block that contains data generated by the attacker’s JavaScript, so he knows what’s in it.
Recovering the cookie data
When there’s a collision, we know that two blocks encrypted to the same output.
Let’s assume that the third condition listed above is satisfied, and the collision happened between a block containing the unknown data, and a block that contained known data.
We’ll call the block with the unknown cookie in it block U, and the block with known plaintext (generated by the JavaScript) K.
From the description of CBC mode above, we know that:
CU = E(PU XOR CU-1), CK = E(PK XOR CK-1)
Of course, the collisions means that CU = CK, and if the encrypted values are the same after using the same algorithm with the same key, then the inputs must have been the same, too, so:
PU XOR CU-1 = PK XOR CK-1
Note that we can rearrange this equation and get:
PU = PK XOR CK-1 XOR CU-1
We know CU-1 and CK-1, because those blocks are part of the encrypted data we sniffed and stored, and we know PK because we chose it ourselves.
Therefore we can now calculate PU directly.
In other words, we just decrypted 64 bits, or eight bytes, of the original HTTP request, which contains (we hope) something like a login cookie or other critical data worth expending all that effort on.
Does it work?
In the real world, login cookies are usually longer than eight characters, and are therefore almost certain to take up at least two 64-bit blocks.
So once you’ve won the “birthday gamble” for the first eight bytes, you get to do it all over again to get the next eight bytes, and so on.
In their experiments, the researchers set themselves a target of recovering a 16-byte session cookie, using a Developer Edition version of Firefox to handle the connections and to run the JavaScript needed:
On Firefox Developer Edition 47.0a2, with a few dozen workers running in parallel, we can send up to 2000 requests per second in a single TLS connection. In our experiment, we were lucky to detect the first collision after only 25 minutes (220.1 requests), and we verified that the collision revealed [the plaintext we were after …T]he full attack should require 236.6 blocks (785 GB) to recover a two-block cookie, which should take 38 hours in our setting. Experimentally, we have recovered a two-block cookie from an HTTPS trace of only 610 GB, captured in 30.5 hours.
In short, this is not a very practical attack: in a day or so, you may be able to steal a login cookie for a user’s session, if they (and the web server) allow the connection to stay open for that long.
But the attack does work, and it could be used in real life, for a few very simple reasons:
- 232, or just over 4 billion, must be treated as a tiny number these days when it comes to cryptographic hacking.
- A web connection that lasts for more than a day, and exchanges 1TB of data, is no longer out of the ordinary.
- Attacks like this only ever get faster, as computers get faster and can handle more memory for bigger data sets.
- Ciphers like 3DES are still widely supported for backward compatibility, even when they aren’t needed.
As the researchers point out:
We found that 86% [of Alexa’s top one million] servers that support TLS include Triple-DES as one of the supported ciphers. Moreover, 1.2% of these servers are configured in such a way that they will actually pick a Triple-DES based ciphersuite with a modern browser, even though better alternatives are available. (In particular many of these servers support AES-based ciphersuites, but use Triple-DES or RC4 preferentially.)
What to do?
- If you are using a VPN such as OpenVPN that uses 64-bit block cipher by default, switch to AES instead, with 128-bit blocks.
- If your web server doesn’t need 3DES support, remove it from the list.
- If you support 3DES for old browsers, make sure you don’t accept it ahead of better ciphers if the connecting client supports them.
- If you accept a 64-bit cipher, limit the time or the number of requests for which the connection will stay open.
Follow @NakedSecurity
Follow @duckblog
Article source: http://feedproxy.google.com/~r/nakedsecurity/~3/QRM32bbPAVY/