These days, a lot of your data gets encrypted when you save it to disk or send it over the internet.
The data gets decrypted again when you read it back in or after it’s received at the other end.
For that, you need some sort of cryptographic algorithm – what’s known in the jargon as a symmetric cipher or secret-key encryption.
Symmetric ciphers use the digital equivalent of a key, typically a string of characters, to lock and unlock the data.
In this article, we’ll take a journey through the history of symmetric ciphers during the pen-and-paper era, before mechanical and electronic encryption devices came onto the scene.
From Julius Caesar in the first century BC to Joseph Mauborgne at the end of the second millennium AD, we’ll look at:
- How each generation of algorithms worked.
- Why they fell by the wayside.
- What was better – or not! – about what came next.
The good news is that you won’t need to wade through any advanced mathematics to appreciate this fascinating story…
..and even though we’ll end our journey just over 100 years ago, during World War One, there’s still plenty we can learn from it.
We’ll start where many cryptographic histories kick off, with the Caesar cipher, named after military commander and political supremo Julius Caesar, who lived, fought and ruled in the first century BC.

As you can imagine, given the writing technology available at the time, Caesar needed a system that was simple both to use and to explain.
If you want to send an encrypted message to someone else, they have to be able to learn the system easily and to unscramble messages reliably.
Casear simply moved each letter of the alphabet back three places:

There are also letters to Cicero and to friends on private matters in which, if things were confidential, he used a cipher, rearranging the alphabet so the words were unintelligible. Anyone who wanted to decipher them had to shift the letters along four places, writing D for A and so on. [Informal translation by Naked Security.]
(In English, we describe D as three letters after A in the alphabet, but the Ancient Romans included both ends of the range when counting, so that moving from A to D in Latin is a shift of four places.)
The most obvious weakness of the Caesar cipher is that there are only 25 different possible keys, assuming the 26-letter alphabet used for English.
In the jargon, we say that the keyspace is 25:

In other words, the easiest attack on a Caesar cipher is what’s now known as brute force – try every possible key until you hit the jackpot, assuming that the original message makes sense and can be recognised easily.
LESSON 1 – KEYSPACE
Encryption algorithms need enough keyspace to make a brute force attack unfeasible, or else the crooks can always win.
Remember that when you are encrypting data that might fall into an attacker’s hands, you are protecting against what’s called an offline attack That’s where you have no control over how much time, energy, computing power or trickery the Bad Guys might invest in cracking the puzzle.
A five-digit PIN code is just about good enough to keep your bank card secure because the PIN isn’t stored on the card and can’t be recovered from it. The only way to figure out the PIN, given the card, is an online attack, where you present the card at an ATM, enter a PIN and ask the system to see if it’s correct. After three mistakes, the card gets invalidated, and the attack has failed.
But when the crooks are trying to decrypt already-stolen data, you have no way of limiting how hard they can try, so you need to assume they may try for months, or even years. Offline attacks can draft in thousands of powerful servers, or even build special-purpose cryptographic cracking machines.
Increasing the keyspace
One way to increase the keyspace of a Caesar cipher is to shuffle the alphabet rather than just to shift it.
The key becomes more complex to create and to remember, being a 26-letter alphabetic permutation, but the number of possible keys increases enormously:

You have 26 letters to choose from when you pick the replacement character for A, then 25 replacements for B, and so on, for a total of 26 × 25 × 24 … 3 × 2 × 1 different keys.
That’s a whopping number: 403,291,461,126,605,635,584,000,000, in fact.
That number is bigger than 287, meaning that when written out in binary, it needs 88 bits.
The US security standards body NIST currently recommends at least 128-bit keys for new cryptographic software, but 80 bits is still considered acceptable for legacy applications, more than 2000 years after Caesar.
Unfortunately, just having lots of possible keys is not enough on its own.
Whether you shift or shuffle the alphabet, a Casear cipher always replaces the letters in the same way.
If the first E in your document encrypts to X, for instance, then every other E will come out as X as well.
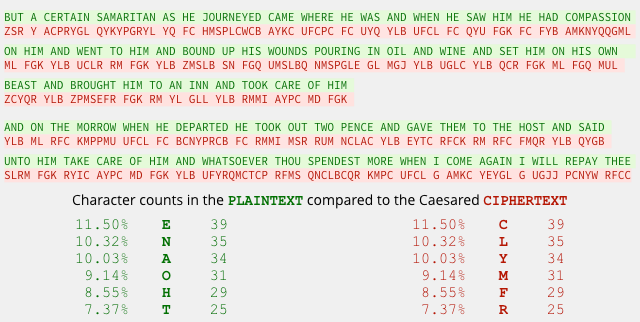
In other words, the letter frequencies in the plaintext will be mirrored exactly in the ciphertext, as in this example from the text of the King James Version (KJV) of the Bible:
If the attackers know the likely topic of the message they want to crack, they can use the statistical properties of other material on the subject to help them recover the key.
Here are the letter frequencies in the KJV, compared with the frequencies in our encrypted fragment:

To crack a Caesar cipher, we start by making a reasonable guess – here, we’ll start with the likely assumption that C=E, simply because C is the most common letter in the ciphertext, and E the most common in unencrypted English:
... . .E..... ......... .. .E .....E.E. ...E ..E.E .E ... ... ..E. .E ... ... .E ...
.......... .. ... ... .E.. .. ... ... ..... .. ... ...... ....... .. ... ... ...E ...
.E. ... .. ... ... .E... ... ....... ... .. .. ... ... .... ...E .. ...
... .. ..E ...... ..E. .E .E....E. .E .... ... ... .E..E ... ...E ..E. .. ..E ....
... .... .... ... ...E ...E .. ... ... ......E.E. .... ..E..E.. ...E ..E. . ...E
..... . .... .E... ..EE
This is 17th century language, so it’s a good guess that the final word ..EE is going to be THEE, which helps us figure out two more of our top six letters, assuming that R=T and F=H:
..T . .E.T... ......T.. .. HE .....E.E. ...E .HE.E HE ... ... .HE. HE ... H.. HE H..
.......... .. H.. ... .E.T T. H.. ... ..... .. H.. ...... ....... .. ... ... ...E ...
.ET H.. .. H.. ... .E..T ... .....HT H.. T. .. ... ... T... ...E .. H..
... .. THE ...... .HE. HE .E...TE. HE T... ..T T.. .E..E ... ...E THE. T. THE H..T
... .... ..T. H.. T..E ...E .. H.. ... .H.T..E.E. TH.. ..E..E.T ...E .HE. . ...E
..... . .... .E... THEE
The Ts, Hs and Es are combining neatly so far, so we’ll accept these substitutions for now, and look at the rest of our top six list, the letters A, N and O.
The letters A and N are common partly because the words AN and AND are common, and KJV verses frequently begin with AND.
(The word BUT commonly starts sentences too, so we’re happy to say that you can forget the “rule” you were taught at school about not using conjunctions to begin sentences.)
The first verse starts ..T, which could indeed stand for BUT, so let’s guess that the second verse starts with AND, which comes out as YLB in the ciphertext.
Given that AND is a common word, our guess is supported by the presence of several other instances of YLB in the encrypted data.
Let’s try setting A=Y, N=L and B=D:
..T A .E.TA.N .A.A..TAN A. HE ....NE.ED .A.E .HE.E HE .A. AND .HEN HE .A. H.. HE HAD
....A....N .N H.. AND .ENT T. H.. AND ...ND .. H.. ...ND. .....N. .N ... AND ..NE AND
.ET H.. .N H.. ..N .EA.T AND .....HT H.. T. AN .NN AND T... .A.E .. H..
AND .N THE ...... .HEN HE DE.A.TED HE T... ..T T.. .EN.E AND .A.E THE. T. THE H..T
AND .A.D .NT. H.. TA.E .A.E .. H.. AND .HAT..E.E. TH.. ..ENDE.T ...E .HEN . ...E
A.A.N . .... .E.A. THEE
Looking good!
At this point, .HEN can’t be THEN, so it’s probably WHEN.
We’ve also got SAMARITAN as a likely match for .A.A..TAN, given what we know about Middle Eastern history, and DEPARTED jumps out as a probable fit for DE.A.TED.
Adding in our earlier guess that the first verse starts BUT, and we are as good as finished:
BUT A .ERTAIN SAMARITAN AS HE ..URNE.ED .AME WHERE HE WAS AND WHEN HE SAW HIM HE HAD
..MPASSI.N .N HIM AND WENT T. HIM AND B.UND UP HIS W.UNDS P.URIN. IN .I. AND WINE AND
SET HIM .N HIS .WN BEAST AND BR.U.HT HIM T. AN INN AND T... .ARE .. HIM
AND .N THE M.RR.W WHEN HE DEPARTED HE T... .UT TW. PEN.E AND .A.E THEM T. THE H.ST
AND SAID UNT. HIM TA.E .ARE .. HIM AND WHATS.E.ER TH.U SPENDEST M.RE WHEN I ..ME
A.AIN I WI.. REPA. THEE
The rest follows easily, based on letter frequencies alone.
LESSON 2 – MIX-UP
Encryption algorithms need to mix their data up sufficiently to disguise any patterns that might leak from the plaintext to the ciphertext. Simply put, the output of a decent encryption algorithm should be indistinguishable by statistical analysis from a string of random numbers.
Note, however, that an algorithm with no obvious biases in its output is not secure on that basis alone. If you encrypt data that’s already been compressed, for example, you are starting with random-looking input and so even cryptographically inadequate mixing may make the output pass most or all well-known tests for randomness.
But any encryption algorithm that does have biases in its output is almost certain to be no good.
Increasing the mix
By the 1500s, cryptography expert Giovan Battista Bellaso had come up with a way of improving the Caesar cipher without greatly increasing the complexity of the encryption process.
His cipher is now known as the Vigenere, named (or mis-named, if you prefer) after the diplomat and cryptographer Blaise de Vigenère, who came up with a different but related idea later in the 16th century.

This system uses multiple Caesar ciphers in sequence to disguise patterns in the input, and to skew the frequency distribution of the ciphertext.
You think of a password, such as CRYPT, and then use each letter of the key in turn to pick a different Caesar shift for each input letter, using a table like this:
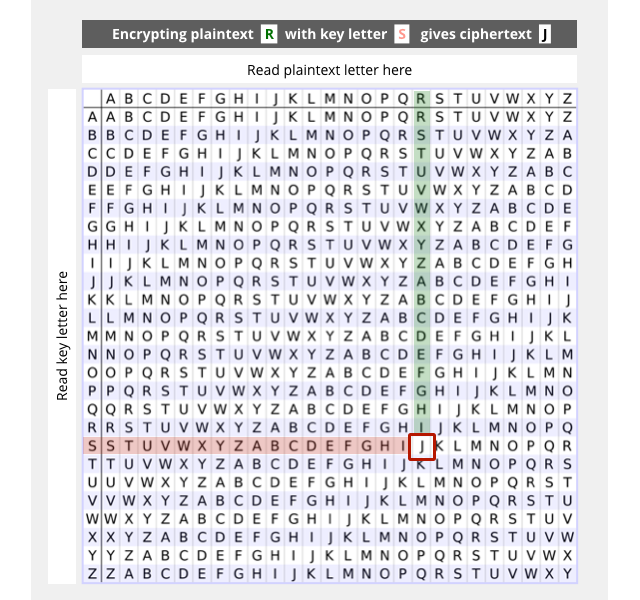
Our first input word is BUT, and the first three letters of the key are CRY, so we use the third row, labelled C, to shift B forward two places to D; we shift U using row R, giving L; and T is “Caesared” with row Y to produce R.
Last time, every letter in BUT was shifted the same amount to give ZSR; this time we end up with DLR.
When we reach the end of the key, we wrap round and repeat the sequence of different Caesar shifts again.
You can clearly see how this throws off the distribution of letter counts in the encrypted data, as well as helping to disguise repeated letters and words in the input:
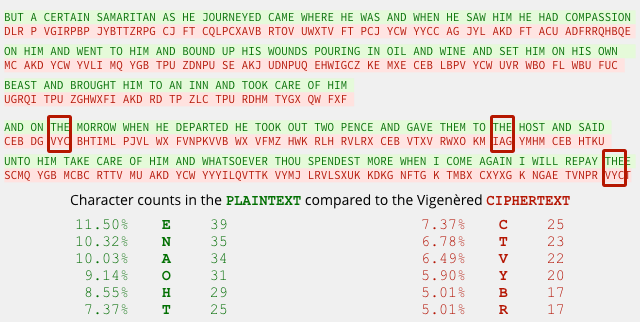
But there’s still not enough mixing going on – with only five different Caesar shifts, there’s a 1-in-5 chance that any repeated text will remain the same in the encrypted output.
For example, in the second verse, THE comes out first as VYC and then as IAG, but in the word THEE at the end, the letters THE are re-aligned with the key in a way that once again produces VYC.
Also, at heart, a Vigenere cipher with a key of N characters is really just N separate Caesar ciphers, each of which can be solved separately using letter frequencies, as we did above.
To figure out the likely length of the key, we can try counting the frequency of every second byte, then every third byte, and so on, looking for a split that gives a similar frequency to unencrypted text:
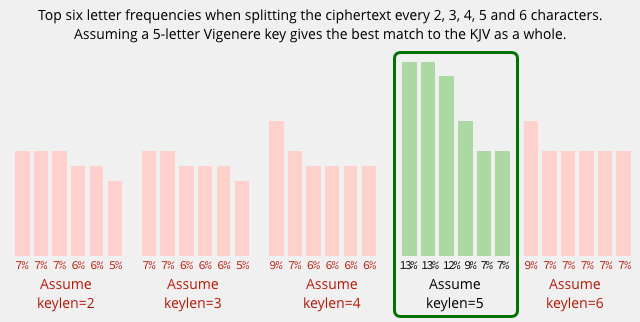
When we guess the keylength correctly, we suddenly see a frequency distribution that lines up with the input data much better than any of the others.
LESSON 3 – COMPLEXITY
Encryption algorithms don’t necessarily get better just because you add a bit more complexity.
The Vigenere cipher is harder to crack than a pure Caesar cipher, but at heart it isn’t sufficiently different, and can be cracked using exactly the same techniques applied slightly differently.
Processing more data at a time
The problem with both the Caesar and Vigenere ciphers is the one-letter-at-a-time approach.
Even if you don’t have digital computers at your disposal, frequency analysis based on individual characters is just too easy.
Encrypting more letters at one go – essentially using an much bigger alphabet than just A to Z – was the approach taken by nineteenth century scientist and prolific inventor Charles Wheatstone.
His cipher became known as Playfair, after Lyon Playfair, a scientist and politician who promoted its use.

Playfair encrypts two characters at a time, so that an attacker needs a frequency table for all two-letter pairs, or digraphs, from AA to ZZ.
One letter of the alphabet, such as Q, is dropped, or two letters, such as I and J, are combined, so the 25 remaining letters will fit into a 5×5 alphabetic grid.
After entering a permutation of the alphabet into the grid, you use the mixed-up grid to encrypt two letters at a time.
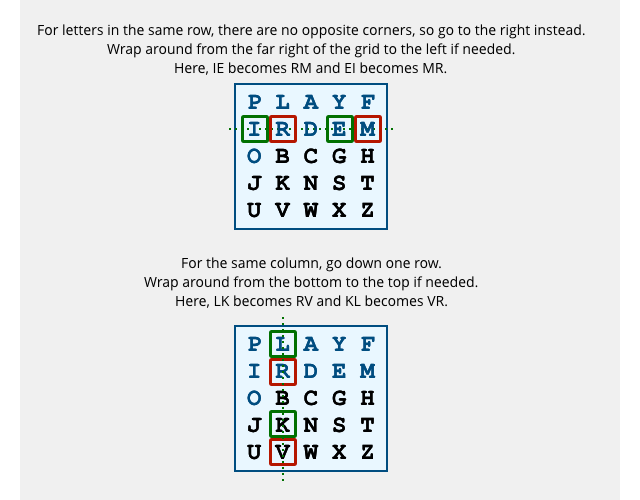
The method involves imagining a rectangle with the plaintext letters at the top and bottom corners, and then writing out the letters at the opposite corners of the rectangle as your ciphertext:

If the two letters are in the same row or column, you simply use the two letters to the right or below instead:
The two-letters-at-a-time substitution makes statistical analysis harder, because there are 26 × 26 = 676 letter pairs to keep track of.
Unfortunately, using a 676-entry “alphabet” still isn’t enough to put Playfair beyond the reach of an attacker working manually with pen and paper.
There are also various anomalies in the Playfair algorithm that reduce its randomness in a way that helps crackers.
One problem is that there’s no easy way to encrypt paired letters, such as the OO in BOOK or the NN in FUNNY, because you need two different letters in the grid to make a substitution rectangle.
The algorithm therefore requires you to add dummy characters, such as X or Z, between paired letters in order to force them to be encrypted as two different letters.
But the absence of letter pairs in the input means that you’ll never see letter pairs in the ciphertext.
In other words, the ciphertext can never end up truly random-looking – you should get the same letter twice in a row 1/26th of the time (3.8%) if you’re relying on chance – and so the Playfair cipher can never satisfy the mix-up rule we laid out above in Lesson 2.
Also, because of the way the character substitution process works, reversing any letter pair will produce a reversed ciphertext pair.
If RS encrypts as EK, as shown above, then SR will come out as KE, being the diagonal corners of the same substitution rectangle in the opposite order.
So, if you were to see the ciphertext AM RV VR, and the letter pair AM occurred elsewhere fairly regularly, you might immediately guess that the plaintext word was INDEED.

Playfair was subsequently extended to a version that used two squares of alphabetic patterns, and even to a four-squared variant that produced better randomness by allowing you to encrypt letter pairs such as OO and EE directly.
But the 2-square and 4-square variants were much more cumbersome to use, and still didn’t address the problem that the underlying cipher always produced the same output for the same input.
The words THE and AND, for instance, can only form the letter pairs TH Ex, xT HE, AN Dx and xA ND, which is why the digraphs TH, HE, AN and ND stand out at the top of the frequency chart above.
LESSON 4 – RANDOMNESS
Extra algorithmic complexity can help, but isn’t enough on its own.
Playfair ciphers feel quadratically more complex than Caesar ciphers at first, because you’re dealing with 262 encryption units at a time instead of just 26.
But the same frequency-counting techniques that help you crack Caesar and Vignere work with Playfair too, because the output simply isn’t random enough.
One cipher to rule them all
We generally don’t rely on pen-and-paper encryption any more, because we simply can’t match by hand the amount of mixing-mincing-shredding-and-liquidising that computers can perform when scrambling data.
Modern encryption algorithms like the Advanced Encryption Standard (AES) use a cryptographic alphabet in which each “letter” is 16 bytes long, and the cryptographic keys are up to 32 bytes long:

AES can encrypt the input 15CHARSATATIME-x all in one go, as if it were a single letter in a truly enormous alphabet, using a beefy key such as AESKEYCANBE256BITSWHICHIS32BYTES.
This sort of algorithmic complexity just wasn’t practical in the pen-and-paper era:

Despite the enormous key and alphabet sizes, however, even AES doesn’t offer perfect security.
With the right combination of wits, time, computing power and luck, AES-encrypted data can sometimes be cracked.
Interestingly, however, a perfectly secure cipher – perfect in both the mathematical and the practical senses – does exist, and it was invented more than 100 years ago during the First World War by US Army officer Joseph Mauborgne.

It’s known as a one-time pad, and in simple terms it’s just a Vigenere cipher in which the key is totally random and never repeats – in other words, the key is as long as the text:

The reason it’s perfectly secure in a mathematical sense is that every possible key is equally likely, and because the key is as long as the input, every possible decryption is equally likely.
There’s simply no way to tell which key, and therefore which plausible decryption, is the right one:

Of course, for all that the one-time pad can be made be perfectly secure in practice, it’s not very practical.
In particular, the keys really do have to be random; every byte of every key must be used at most twice (once for encryption and once for decryption); and the sender and recipient need to keep their keystreams synchronised and secret at all times.
Generating and distributing that much key material securely is both costly and complicated, which is why one-time pads have traditionally been used only by intelligence agents in the field or for top-level diplomatic communications.
In fact, the strength of the one-time pad can also serve as its enemy: if you run out of key material, you might be tempted to use the same key for more than one message.
Doing so, however, ruins the “perfect unpredictability” that comes from truly random keystream data.
By all accounts, in a project known in the trade as Venona, the US successfully decrypted small amounts of top-secret Soviet diplomatic traffic sent between about 1942 and 1948.
Apparently, the organisation that produced Soviet one-time pads struggled to keep up with wartime demand, and sometimes reused old printing plates to speed up the creation of key pages.
This resulted in occasional messages that were encrypted with the same keystream, and those messages could, in theory at least, be cracked.
The lessons learned
The pen-and-paper history of cryptography and cryptanalysis is fascinating, not least because you don’t need to wade through advanced mathematics to get a feel for the hack-and-counter-hack nature of the field.
It’s also relevant, because the evolution of cryptographic and cryptographic algorithms teaches us some fundamental lessons that apply even in the modern era:
- Key size matters. A cryptosystem in which a crook can feasibly try every possible key just isn’t good enough, so you need to be sure that the underlying algorithms put what’s known as a brute-force search out of reach.
- Key size alone is not enough. A cryptosystem in which a crook can take shortcuts to sidestep a brute force attack is no good either.
- Randomness matters. A cryptosystem that shows any sort of bias in its output shouldn’t be trusted, because there may be systematic weaknesses in how well it mixes up its input.
- Randomness alone isn’t enough. A cryptosystem must produce output that seems random, but data isn’t secure simply because it passes all known tests for randomness.
- A correct algorithm alone isn’t enough. A cryptosystem can’t meet its security promises if it isn’t used correctly, for example by turning a one-time pad into a two-time pad.
The good news about cryptography in 2019 is that there are few technical reasons for cutting corners and not “doing it right”.
Modern computers – even if you add low-cost Internet of Things devices to your list – generally have sufficient computing power to support the latest, fit-for-purpose algorithms.
Modern encryption algorithms are generally free to use, and high-quality implementations are freely available if you search wisely.
What next?
Our biggest problem these days seems to be avoiding the interference of well-meaning governments who want to regulate the use of encryption in ways that deliberately weaken it.
At Sophos, we’ve long been against forcing vendors to use cryptographic algorithms in a way that purposely prevents them meeting their security promises – such as mandating the inclusion of so-called backdoors.
As cryptographers love to say, “Attacks only ever get better,” so we might as well keep our defences up to scratch…

Article source: http://feedproxy.google.com/~r/nakedsecurity/~3/WhjvWJXh1Cs/