 You probably didn’t miss the news – and the fallout that followed – about Adobe’s October 2013 data breach.
You probably didn’t miss the news – and the fallout that followed – about Adobe’s October 2013 data breach.
Not only was it one of the largest breaches of username databases ever, with 150,000,000 records exposed, it was also one of the most embarrassing.
The leaked data revealed that Adobe had been storing its users’ passwords ineptly – something that was surprising, because storing passwords much more safely would have been no more difficult.
Following our popular article explaining what Adobe did wrong, a number of readers asked us, “Why not publish an article showing the rest of us how to do it right?”
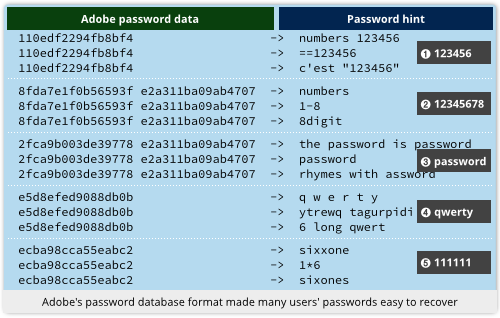
Here you are!
Just to clarify: this article isn’t a programming tutorial with example code you can copy to use on your own server.
Firstly, we don’t know whether your’re using PHP, MySQL, C#, Java, Perl, Python or whatever, and secondly, there are lots of articles already available that tell you what to do with passwords.
We thought that we’d explain, instead.
Attempt One – store the passwords unencrypted
On the grounds that you intend – and, indeed, you ought – to prevent your users’ passwords from being stolen in the first place, it’s tempting just to keep your user database in directly usable form, like this:

If you are running a small network, with just a few users whom you known well, and whom you support in person, you might even consider it an advantage to store passwords unencrypted.
That way, if someone forgets their password, you can just look it up and tell them what it is.
Don’t do this, for the simple reason that anyone who gets to peek at the file immediately knows how to login as any user.
Worse still, they get a glimpse into the sort of password that each user seems to favour, which could help them guess their way into other accounts belonging to that user.
Alfred, for example, went for his name followed by a short sequence number; David used a date that probably has some personal significance; Eric Cleese followed a Monty Python theme; while Charlie and Duck didn’t seem to care at all.
The point is that neither you, nor any of your fellow system administrators, should be able to look up a user’s password.
It’s not about trust, it’s about definition: a password ought to be like a PIN, treated as a personal identification detail that is no-one else’s business.
Attempt Two – encrypt the passwords in the database
Encrypting the passwords sounds much better.
You could even arrange to have the decryption key for the database stored on another server, get your password verification server to retrieve it only when needed, and only ever keep it in memory.
That way, users’ passwords never need to be written to disk in unencrypted form; you can’t accidentally view them in the database; and if the password data should get stolen, it would just be shredded cabbage to the crooks.
This is the approach Adobe took, ending up with something similar to this:

→ For the sample data above we chose the key DESPAIR and encrypted each of the passwords with straight DES. Using DES for anything in the real world is a bad idea, because it only uses 56-bit keys, or seven characters’ worth. Even though 56 bits gives close to 100,000 million million possible passwords, modern cracking tools can get through that many DES passwords within a day.
You might consider this sort of symmetric encryption an advantage because you can automatically re-encrypt every password in the database if ever you decide to change the key (you may even have policies that require that), or to shift to a more secure algorithm to keep ahead of cracking tools.
But don’t encrypt your password databases reversibly like this.
You haven’t solved the problem we mentioned in Attempt One, namely that neither you, nor any of your fellow system administrators, should be able to recover a user’s password.
Worse still, if crooks manage to steal your database and to acquire the password at the same time, for example by logging into your server remotely, then Attempt Two just turns into Attempt One.
By the way, the password data above has yet another problem, namely that we used DES in such a way that the same password produces the same data every time.
We can therefore tell automatically that Charlie and Duck have the same password, even without the decryption key, which is a needless information leak – as is the fact that the length of the encrypted data gives us a clue about the length of the unencrypted password.
We will therefore insist on the following requirements:
- Users’ passwords should not be recoverable from the database.
- Identical, or even similar, passwords should have different hashes.
- The database should give no hints as to password lengths.
Attempt Three – hash the passwords
Requirement One above specifies that “users’ passwords should not be recoverable from the database.”
At first glance, this seems to demand some sort of “non-reversible” encryption, which sounds somewhere between impossible and pointless.
 But it can be done with what’s known as a cryptographic hash, which takes an input of arbitrary length, and mixes up the input bits into a sort of digital soup.
But it can be done with what’s known as a cryptographic hash, which takes an input of arbitrary length, and mixes up the input bits into a sort of digital soup.
As it runs, the algorithms strains off a fixed amount of random-looking output data, finishing up with a hash that acts as a digital fingerprint for its input.
Mathematically, a hash is a one-way function: you can work out the hash of any message, but you can’t go backwards from the final hash to the input data.
A cryptographic hash is carefully designed to resist even deliberate attempts to subvert it, by mixing, mincing, shredding and liquidising its input so thoroughly that, at least in theory:
- You can’t create a file that comes out with a predefined hash by any method better than chance.
- You can’t find two files that “collide”, i.e. have the same hash (whatever it might be), by any method better than chance.
- You can’t work out anything about the structure of the input, including its length, from the hash alone.
Well-known and commonly-used hashing algorithms are MD5, SHA-1 and SHA-256.
Of these, MD5 has been found not to have enough “mix-mince-shred-and-liquidise” in its algorithm, with the result that you can find two files with the same hash very much faster than by chance.
This means it does not meet its original cryptographic promise – so do not use it in any new project.
SHA-1 is computationally quite similar to MD5, and many experts consider that it might soon be found to have similar problems to MD5 – so you may as well avoid it.
We’ll use SHA-256, which gives us this if we apply it directly to our sample data (the hash has been truncated to make it fit neatly in the diagram):

The hashes are all the same length, so we aren’t leaking any data about the size of the password.
Also, because we can predict in advance how much password data we will need to store for each password, there is now no excuse for needlessly limiting the length of a user’s password. (All SHA-256 values have 256 bits, or 32 bytes.)
→ It’s OK to set a high upper bound on password length, e.g. 128 or 256 characters, to prevent malcontents from burdening your server with pointlessly large chunks of password data. But limits such as “no more than 16 characters” are overly restrictive and should be avoided.
To verify a user’s password at login, we keep the user’s submitted password in memory – so it never needs to touch the disk – and compute its hash.
If the computed hash matches the stored hash, the user has fronted up with the right password, and we can let him login.
But Attempt Three still isn’t good enough, because Charlie and Duck still have the same hash, leaking that they chose the same password.
Indeed, the text password will always come out as 5E884898DA28..EF721D1542D8, whenever anyone chooses it.
That means the crooks can pre-calculate a table of hashes for popular passwords – or even, given enough disk space, of all passwords up to a certain length – and thus crack any password already on their list with a single database lookup.
Attempt Four – salt and hash
We can adapt the hash that comes out for each password by mixing in some additional data known as a salt, so called because it “seasons” the hash output.
A salt is also known as a nonce, which is short for “number used once.”
Simply put, we generate a random string of bytes that we include in our hash calculation along with the actual password.
The easiest way is to put the salt in front of the password and hash the combined text string.
The salt is not an encryption key, so it can be stored in the password database along with the username – it serves merely to prevent two users with the same password getting the same hash.
For that to happen they would need the same password and the same salt, so if we use 16 bytes or more of salt, the chance of that happening is small enough to be ignored.
Our database now looks like this (the 16-byte salts and the hashes have been truncated to fit neatly):
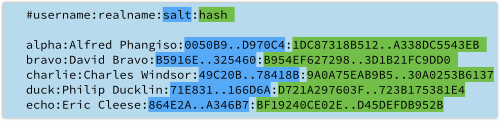
The hashes in this list, being the last field in each line, are calculated by creating a text string consisting of the salt followed by the password, and calculating its SHA-256 hash – so Charlie and Duck now get completely different password data.
Make sure you choose random salts – never use a counter such as 000001, 000002, and so forth, and don’t use a low-quality random number generator like C’s random().
If you do, your salts may match those in other password databases you keep, and could in any case be predicted by an attacker.
By using sufficiently many bytes from a decent source of random numbers – if you can, use CryptoAPI on Windows or /dev/urandom on Unix-like systems – you as good as guarantee that each salt is unique, and thus that it really is a “number used once.”
Are we there yet?
Nearly, but not quite.
Although we have satisfied our three requirements (non-reversibility, no repeated hashes, and no hint of password length), the hash we have chosen – a single SHA-256 of salt+password – can be calculated very rapidly.

In fact, modern hash-cracking servers costing under $20,000 can compute 100,000,000,000 or more SHA-256 hashes each second.
We need to slow things down a bit to stymie the crackers.
Attempt Five – hash stretching
The nature of a cryptographic hash means that attackers can’t go backwards, but with a bit of luck – and some poor password choices – they can often achieve the same result simply by trying to go forwards over and over again.
Indeed, if the crooks manage to steal your password database and can work offline, there is no limit other than CPU power to how fast they can guess passwords and see how they hash.
By this, we mean that they can try combining every word in a dictionary (or every password from AA..AA to ZZ..ZZ) with every salt in your database, calculating the hashes and seeing if they get any hits.
And password dictionaries, or algorithms to generate passwords for cracking, tend to be organised so that the most commonly-chosen passwords come out as early as possible.
That means that users who have chosen uninventively will tend to get cracked sooner.
→ Note that even at one million million password hash tests per second, a well-chosen password will stay out of reach pretty much indefinitely. There are more than one thousand million million million 12-character passwords based on the character set A-Za-z0-9.
It therefore makes sense to slow down offline attacks by running our password hashing algorithm as a loop that requires thousands of individual hash calculations.
That won’t make it so slow to check an individual user’s password during login that the user will complain, or even notice.
But it will reduce the rate at which a crook can carry out an offline attack, in direct proportion to the number of iterations you choose.
However, don’t try to invent your own algorithm for repeated hashing.
Choose one of these three well-known ones: PBKDF2, bcrypt or scrypt.
We’ll recommend PBKDF2 here because it is based on hashing primitives that satisfy many national and international standards.
We’ll recommend using it with the HMAC-SHA-256 hashing algorithm, repeated 10,000 times or more.
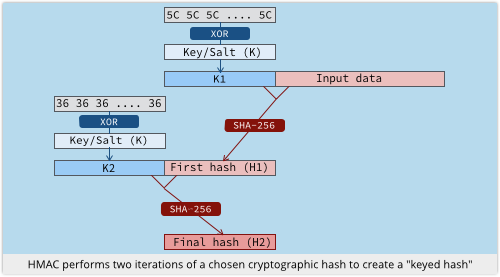
HMAC-SHA-256 is a special way of using the SHA-256 algorithm that isn’t just a straight hash, but allows the hash to be combined comprehensively with a key or salt:
- Take a random key or salt K, and flip some bits, giving K1.
- Compute the SHA-256 hash of K1 plus your data, giving H1.
- Flip a different set of bits in K, giving K2.
- Compute the SHA-256 hash of K2 plus H1, giving the final hash, H2.
In short, you hash a key plus your message, and then rehash a permuted version of the key plus the first hash.
In PBKDF2 with 10,000 iterations, we feed the user’s password and our salt into HMAC-SHA-256 and make the first of the 10,000 loops.
Then we feed the password and the previously-computed HMAC hash back into HMAC-SHA-256 for the remaining 9999 times round the loop.
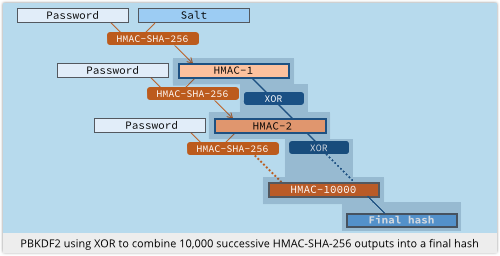
Every time round the loop, the latest output is XORed with the previous one to keep a running “hash accumulator”; when we are done, the accumulator becomes the final PBKDF2 hash.
Now we need to add the iteration count, the salt and the final PBKDF2 hash to our password database:
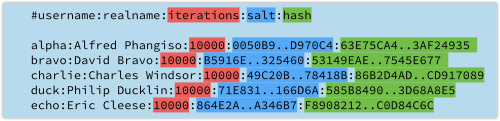
As the computing power available to attackers increases, you can increase the number of iterations you use – for example, by doubling the count every year.
When users with old-style hashes log in successfully, you simply regenerate and update their hashes using the new iteration count. (During successful login is the only time you can tell what a user’s password actually is.)
For users who haven’t logged in for some time, and whose old hashes you now considered insecure, you can disable the accounts and force the users through a password reset procedure if ever they do log on again.
The last word
In summary, here is our minimum recommendation for safe storage of your users’ passwords:
- Use a strong random number generator to create a salt of 16 bytes or longer.
- Feed the salt and the password into the PBKDF2 algorithm.
- Use HMAC-SHA-256 as the core hash inside PBKDF2.
- Perform 10,000 iterations or more. (November 2013.)
- Take 32 bytes (256 bits) of output from PBKDF2 as the final password hash.
- Store the iteration count, the salt and the final hash in your password database.
- Increase your iteration count regularly to keep up with faster cracking tools.
Whatever you do, don’t try to knit your own password storage algorithm.
It didn’t end well for Adobe, and it is unlikely to end well for you.
Image of magnifying glass outline courtesy of Shutterstock.
Article source: http://feedproxy.google.com/~r/nakedsecurity/~3/2EQbUnlArVU/
 GitHub, one of the world’s biggest online repositories of software source code, is warning users to jolly well shape up when it comes to login security.
GitHub, one of the world’s biggest online repositories of software source code, is warning users to jolly well shape up when it comes to login security.
 So it’s a good bet that the attackers are using data derived from Adobe’s recent megabreach.
So it’s a good bet that the attackers are using data derived from Adobe’s recent megabreach. GitHub, one of the world’s biggest online repositories of software source code, is warning users to
GitHub, one of the world’s biggest online repositories of software source code, is warning users to 
 So it’s a good bet that the attackers are using data derived from
So it’s a good bet that the attackers are using data derived from 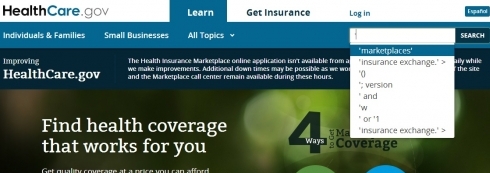
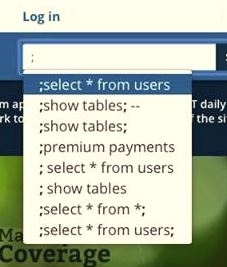 For example, the following no longer appear if you type a semi-colon:
For example, the following no longer appear if you type a semi-colon:

 Young people don’t necessarily recognise the role they play in colluding with bullying behaviour. It’s common for these ‘cyber-bystanders’ to forward something negative that perpetuates the bullying, without realising they’re part of the problem.
Young people don’t necessarily recognise the role they play in colluding with bullying behaviour. It’s common for these ‘cyber-bystanders’ to forward something negative that perpetuates the bullying, without realising they’re part of the problem.