Tor takes on the question, “What if one of us is using loaded dice?”
Here at Naked Security, we’re fond of randomness.
By that, we mean the sort of real randomness that you get from radioactive decay, or background cosmic microwave radiation.
This fondness might seem surprising: randomness and digital computers are strange bedfellows, because computers, and the programs that run on them, are inherently deterministic.
This means that they’ll produce predictable, repeatable results if you feed them the same input over and over.
Most of the time, that’s highly desirable: if your computer adds up a giant list of numbers in a spreadsheet, for example, it will get the same answer every time.
Of course, that doesn’t guarantee the answer is correct – if it was wrong today, it will be wrong tomorrow – but it is at least consistent, and can therefore repeatably and reliably be measured and tested.
Repeatability can be harmful
Sometimes, however, repeatability is bad for security, especially when encryption is involved.
A strong encryption algorithm should disguise any patterns in its input, meaning that its output should be indistinguishable from a random sequence.
But that’s not enough: each random output sequence from each run of the encryptor needs to be unique, and unpredictably so, even if you encrypt the same file twice with the same password.
In other words, you need some good-quality randomness to feed into the encryption algorithm at the start.
An excellent example of why this matters comes from Adobe’s infamous password breach in 2013.
The company encrypted every user’s password with the same key, with no added randomness mixed in.
That meant the encrypted passwords could be sorted into bunches, even though they were supposed to be secret.
From the password hints in the database, which Adobe didn’t encrypt at all, you could therefore use the sloppiest user’s hint to figure the password for a whole bunch of users at a time. (Many users had repeated their passwords in the hint field, directly or thinly disguised.)
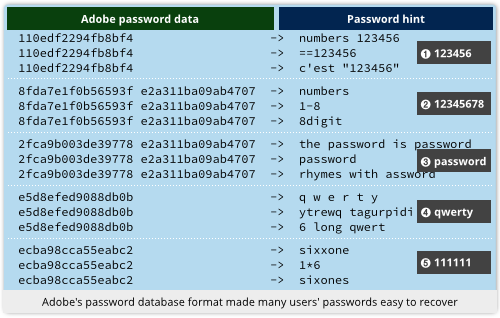
Adobe ought to have chosen a different random modifier, known as a salt, to mix in with each user’s password so that every encryption would produce unique output, even for repeated passwords.
In other words, strong encryption needs a good source of randomness as input if it is to produce usefully-random output.
Tor and randomness
Tor, of course, relies on strong encryption for the anonymity and privacy it provides.
Tor picks a random path for your network traffic so that it passes through an unpredictable selection of nodes in its “onion network”.
When your computer pushes your traffic into Tor, it wraps the data in multiple layers of encryption, in such a way that the next node in the pre-selected path, and only that node, can strip off the next layer of encryption, and only that layer.
That way, each node knows only its immediate neighbours (where your packet came from, and where it’s going next), and thus no one can figure out exactly how it got through the network.
As you can imagine, that means Tor needs plenty of high-quality random input.
Even more importantly, it needs a way to generate randomness for the whole network that can’t be dominated or controlled by individual nodes in the network.
Otherwise, one malevolent or incompetent node could poison the system by introducing “bad randomness.”
Low quality random numbers might make it possible for outside observers to crack the encryption, stripping off some or all of Tor’s anonymity; even worse, carefully chosen “random-looking” but rigged numbers might allow a malicious node to snoop on Tor from the inside.
So, the Tor team came up with a distributed protocol for generating random numbers, so that multiple nodes chime in with what they claim are randomly generated values, and then combine them all into a Shared Random Value (SRV) that is agreed on for the next 24 hours.
COMMIT and REVEAL
Very greatly simplified, the system works like this.
The nodes involved in the randomness protocol spend the first 12 hours of each day inserting what Tor calls a COMMIT value into their messages.
The COMMIT values are cryptographic hashes of a random number each node generated earlier, known as its REVEAL value.
After everyone has nailed their COMMIT values to the virtual mast over a 12-hour period, the nodes start publishing their REVEAL values.
The COMMIT value can be calculated (and thus confirmed) from the REVEAL value, but not the other way around, so that no one can switch out their REVEAL values later on.
That means a malicious node can’t wait until other nodes have REVEALed and sneakily modify its value before REVEALing its own choice.
The REVEAL values are themselves a cryptographic hash of a randomly-generated string of bytes. The original random numbers are hashed as a precaution so that no node ever reveals the actual output of its random generator.
Once all the verifiable REVEAL numbers are nailed to the mast alongside the COMMIT values, the entire set of REVEALs are hashed together to form the SRV.
The theory here is that as long as one or more of the REVEALs really is decently random, then stirring in other non-random data won’t reduce the randomness of the combined SRV, unless some of the non-random data was maliciously chosen with foreknowledge of the other data in the mix.
But none of the REVEALs can be based on anyone else’s choice, because of the COMMIT values that everyone was required to publish first.
In short: even if some of the players have loaded dice, they can’t figure out how to load them to counteract the honesty of your dice.
That sounds like a lot of work for something that you could do for yourself at home by tossing a coin repeatedly…
…but as we have joked (quite seriously!) before, random numbers are far to important to be left to chance.
Follow @NakedSecurity
Follow @duckblog
Article source: http://feedproxy.google.com/~r/nakedsecurity/~3/Y_nK8wHxGQ8/