Phishing with ‘punycode’ – when foreign letters spell English words
The curiously-named system known as punycode is a way of converting words that can’t be written in ASCII, such as the Ancient Greek phrase ΓΝΩΘΙΣΕΑΥΤΟΝ (know yourself) into an ASCII encoding, like this: xn--mxadglfwep7amk6b.
This makes it possible to encode so-called International Domain Names (IDNs) – ones that include non-ASCII characters – using only the Roman letters A to Z, the digits 0 to 9 and the hyphen (-) character.
That’s handy, because the global Domain Name System (DNS), responsible for turning human-friendly server names into computer-friendly network numbers, is restricted to that limited subset of ASCII characters in domain names.
(Back when DNS was codified, storage and network bandwidth were much more precious resources than today, so that limits on the maximum size of everything from character sets to network packets are typically much more restrictive in older protocols.)
Homographs – when two words look alike
If you were to register the domain…
XN--MXADGLFWEP7AMK6B.EXAMPLE.COM.
…some modern apps may recognise the punycoding, and automatically convert the name for display as…
ΓΝΩΘΙΣΕΑΥΤΟΝ.EXAMPLE.COM.
You can see where this is going.
Some letters in the Roman alphabet are the same shape (if not always the same sound) as letters in the Greek, Cyrillic and other alphabets, such as the letters I, E, A, Y, T, O and N in the example above.
So you may be able to register a punycode domain name that looks nothing like a well-known ASCII company name, but nevertheless displays very much like it.
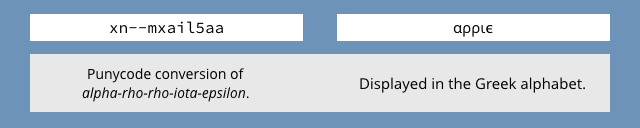
For example, consider the text string consisting of these lower-case Greek letters: alpha, rho, rho, iota, epsilon.
In punycode you get xn--mxail5aa, but when displayed (depending on the fonts you have installed), you get: αρριϵ.
Punycode considered harmful
A security researcher called Xudong Zheng recently wrote an article describing how different browsers take different approaches to homograph problem.
He registered the domain xn--80ak6aa92e.com, which is a Cyrillic version of the above Greek apple trick – an unlikely Cyrillic domain name that just happens to come out as аррӏе when converted back from punycode to “Russian” text.
Interestingly, many browsers take an aggressive stance against this sort of jiggery-pokery.
Safari and Edge, for example, just display it as plain old xn--80ak6aa92e.com, at least if your system settings don’t include any Cyrillic languages:
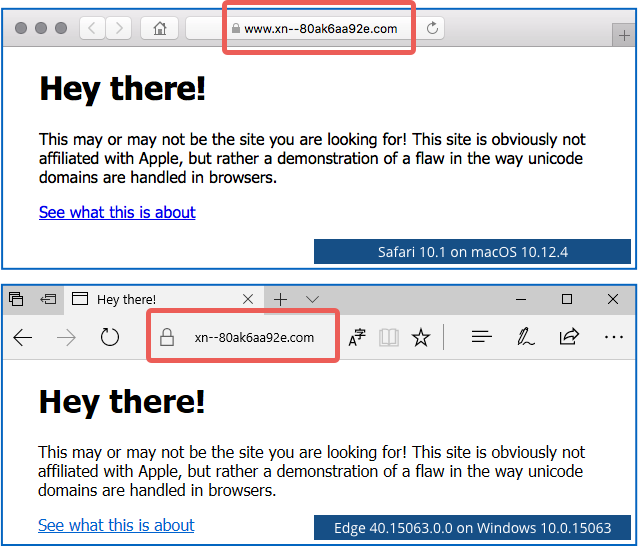
After all, if you can’t read Cyrillic text in the first place, you don’t lose anything by seeing the domain name in its punycode format – in fact, you gain a lot by not seeing it as misleading faux-English text.
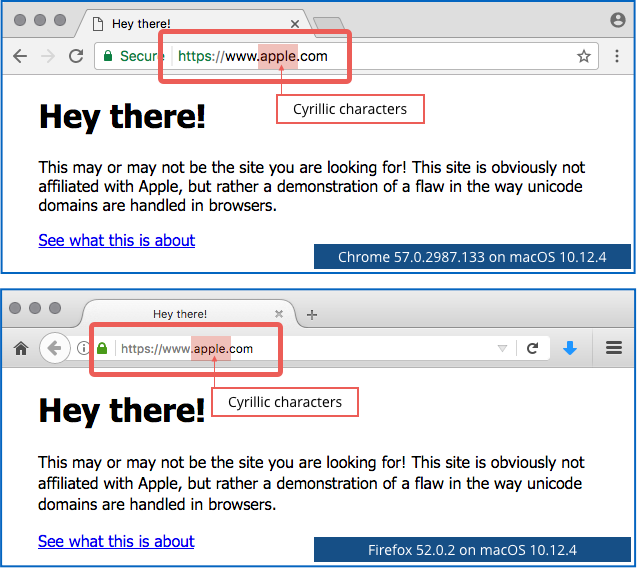
Likewise, Chrome and Firefox won’t automatically decode punycode URLs if they mix multiple alphabets or languages, on the grounds that such text strings are highly unlikely in real life and therefore suspicious.
But both Chrome and Firefox will autoconvert punycode URLs that contain all their characters in the same language, like this:
Preventing “confusables”
Apparently, Chrome will be adding additional browser protection to prevent this autoconversion, starting in the next version (Chrome 58), even though there’s a risk that some genuine non-ASCII domains might subsequently appear in the browser as punycode URLs.
Firefox programmers, on the other hand, are arguing strongly that because the Mozilla Foundation’s desire is to avoid favouritism, and to treat all languages equally, this sort of protection is culturally insensitive and technically undesirable.
They say that the browser isn’t the place for deciding when ASCII should take “first class status” over some other system of writing. (ASCII, by the way, stands for American Standard Code for Information Interchange.)
Some of the Mozilla team suggest, not unreasonably, that the responsibility for preventing “confusable” domains, such as the one used by Xudong in his blog article, lies with the registrars of each top-level domain.
If registrars are, in general, supposed to stop fraudulent or deliberately misleading domain registrations, Mozilla says, then they should be stopping “confusables”, too, in the same way that countries expect their Motor Registries to avoid issuing personalised number plates with potentially offensive or B16OTED combinations of letters and numbers.
Not all of the Mozillans agree, however, pointing out that the risk of appearing “culturally insensitive” in respect of a small number of non-ASCII domain names is a small price to pay for making life harder for phishers and scammers in real life.
After all, deciding whether to allow or disallow a “confusable” domain name in the first place is itself a culturally subjective exercise.
Oh, what a tangled web we weave…
What to do?
Xudong has two good suggestions, to which we’ve added a third of our own:
- Use a password manager, which helps reduce the risk of pasting passwords into any incorrectly-named site. The password manager won’t match your Apple-in-ASCII password with the Apple-in-Cyrillic domain name, no matter what character encoding system is used.
- Force Firefox always to display punycode names. If you don’t (or can’t) read any non-Roman alphabets or writing systems, you lose nothing by going to the
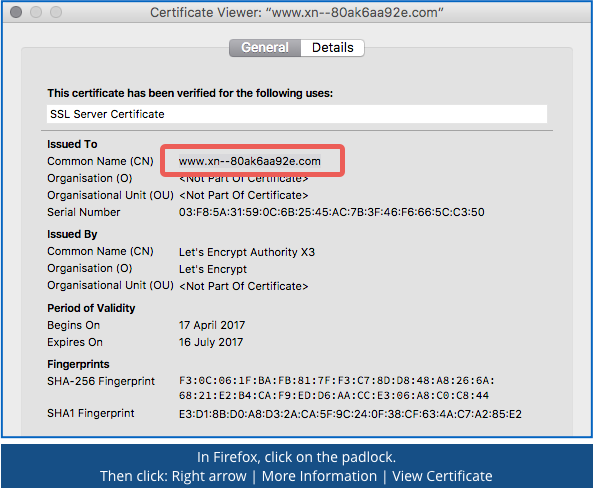
about:configpage and settingnetwork.IDN_show_punycodetotrue. - Click on the padlock to display the HTTPS certificate.. This shows the domain name for which the certificate was issued using the DNS-friendly, ASCII-only format, so if the name starts
xn--then you are looking at a punycode domain, whatever it may look like in the address bar. (Note. Drill right down to the[View Certificate]option.)
Follow @NakedSecurity
Follow @duckblog
Article source: http://feedproxy.google.com/~r/nakedsecurity/~3/PHCvLVCKdh4/